Duke Researchers Continue to Observe the Undesired Third-Party Code on the Duke Network
Duke Researchers Continue to Observe the Undesired Third-Party Code on the Duke Network The Duke-Media Trust project continues to yield important findings on the impact of undesired third-party code on internet users. We are now analyzing two datasets cross-referenced against one another to better understand how this code affects both synthetic profiles and Duke network users. For links to the previous two installments of this monthly blow, visit the project’s website.
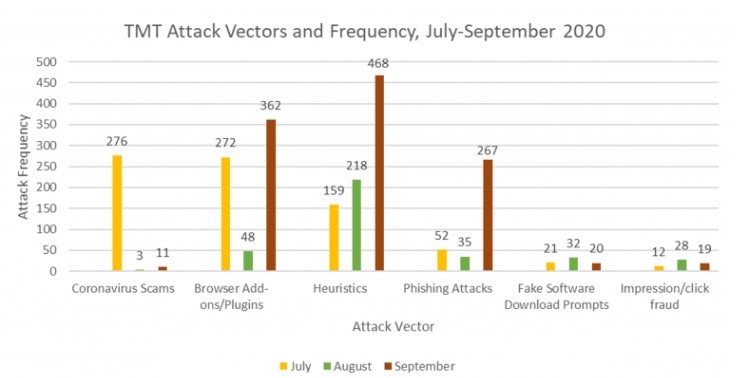
In September, The Media Trust conducted 777,267 scans using the synthetic Duke profiles. Of those scans, 1,147 presented undesired third-party code, which breakdown categorically as follows: 11 Coronavirus scams, 362 browser add-ons/plugins, 468 heuristics, 267 phishing attacks, 20 fake software download prompts, and 19 impression/click fraud detections. Both the number of scans and the number of impressions from September are the highest that our research team has observed to date. The Media Trust conducted over 700,000 scans in August, and only observed 364 malware impressions. Therefore, it is unlikely that the increase in scan volume is a significant contributor to the increase in undesired third-party code that our team observed in the September data.
Specifically, our team is continuing to investigate the increase in browser add-ons, heuristics, and phishing attacks in September. The chart at the bottom of the article demonstrates the changes in all of the attack vectors over time.
According to Pat Ciavolella, Digital Security and Operations Director at The Media Trust, the increase in browser add-ons and phishing attacks may be attributable to an increase in activity from just a few first-party websites and advertising campaigns. In the case of browser add-ons, The Media Trust did not witness the arrival of new ad campaigns during September. Rather, the company observed an increase in volume from the ad campaigns that frequently populate its internet scans. For the phishing attacks, the increase was primarily due to a rise in attacks stemming from a single website.
As for the spike in heuristics, the story looks a bit different. The increase in heuristics was primarily due to increased incidents from one popular news website. Old segments of advertising code continue to serve content in the news vertical of the website, even though the company that owns the third-party domain no longer exists. Without ownership, this code can be commandeered by threat actors who can repurpose it to serve undesired third-party code. Unowned code and abandoned domains are a major threat to the safety of the digital ecosystem. We will provide more analysis on this unowned code and these abandoned domains in a future blog post.
For the September increase in heuristics, the reason why an increase was observed was likely because of differences in the “targeting” of visited websites. When The Media Trust scanned the internet using its synthetic profiles, it is possible that the scans were targeting news articles more so than in previous months. Therefore, the scans may have yielded a disproportionate increase in heuristic third-party code due to the specific mix of the scanned first-party websites.
Moreover, the timing of these increases may not be unusual. The Media Trust is accustomed to witnessing an increase in the volume of undesired code during the fourth quarter of the year. While September is a month earlier than normal, for the last two years The Media Trust has seen an increase in undesired third-party code starting in October. That increase could correspond to increased internet activity as the holidays approach, and more people are using the internet due to the pandemic. We do not have enough data yet to confirm that theory, but in a future blog post we will compare the amount of undesired code to the infection surges of the pandemic to determine if there is further evidence of a correlation.
At the beginning of this blog post, I described how our research team is now analyzing two datasets. The dataset that I have been describing to this point in the blogs is generated by The Media Trust’s synthetic Duke profiles. It provides a glimpse of how threat actors interact with users that appear to be on Duke’s network. In conjunction with analyzing that dataset, our research team is also examining a dataset provided by the Duke Office of Information Technology. It contains all of the instances where a domain from The Media Trust’s blocklist (an extensive collection of domains known to serve undesired third-party code) appeared on the Duke network.
By cross-referencing the data from The Media Trust with the internal data from Duke OIT, our research team is able to understand the internet experience of a Duke user more deeply. Some of our preliminary findings indicate that overlaps do exist between the domains on The Media Trust’s blocklist and those observed on Duke’s network, meaning that undesired third-party code is served to Duke users. A future blog post will explain the findings from that overlap project in more detail.
With three months of data analyzed, our research team has observed that significant volumes of undesired third-party code are delivered to the synthetic profiles. Our team will continue to analyze the datasets from The Media Trust and from Duke in the coming months in the hope of clarifying our understanding of the potential impact on the individuals to whom the code is served. In time, our team hopes to create an actionable plan to mitigate these risks including technical measures and public policy proposals.